Introduction
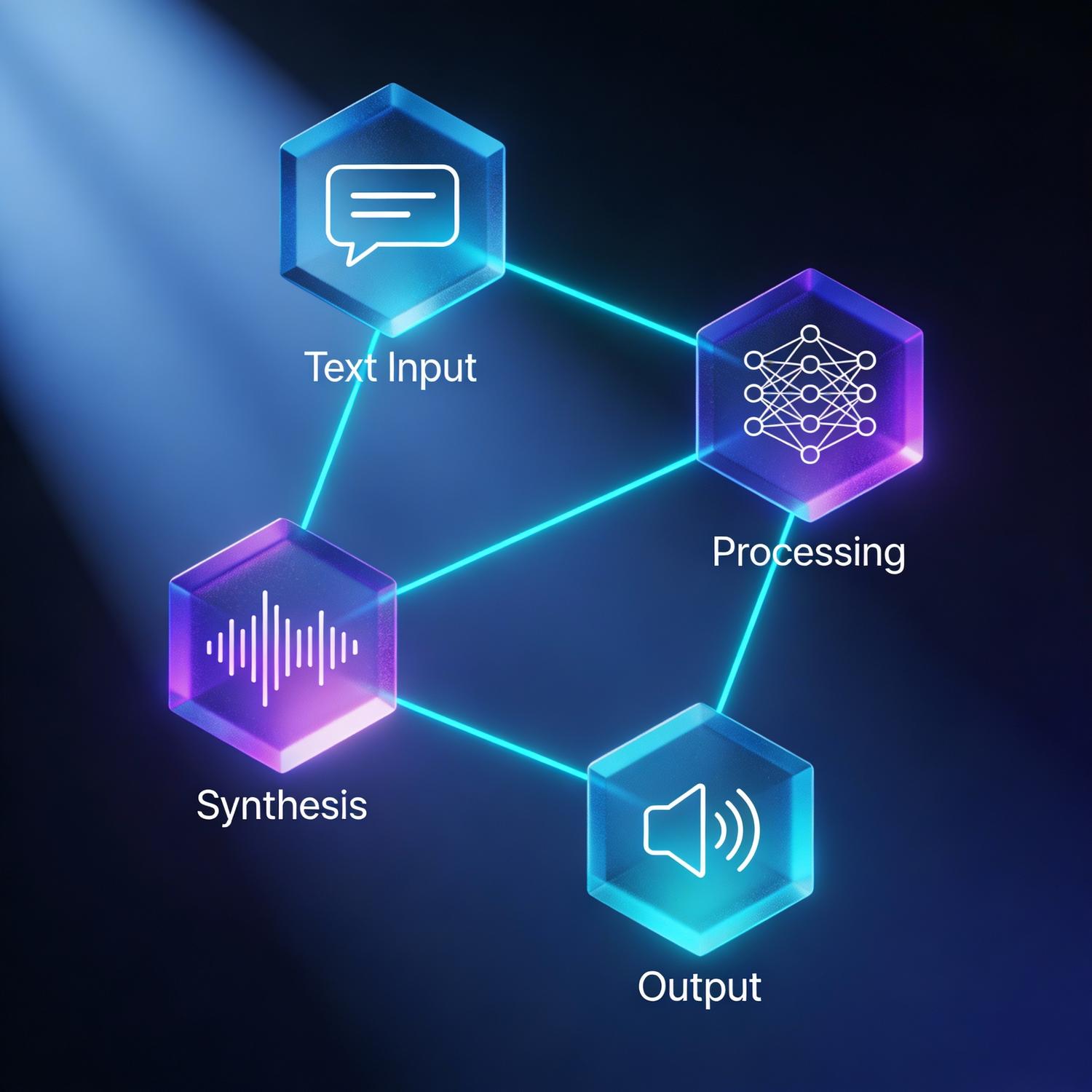
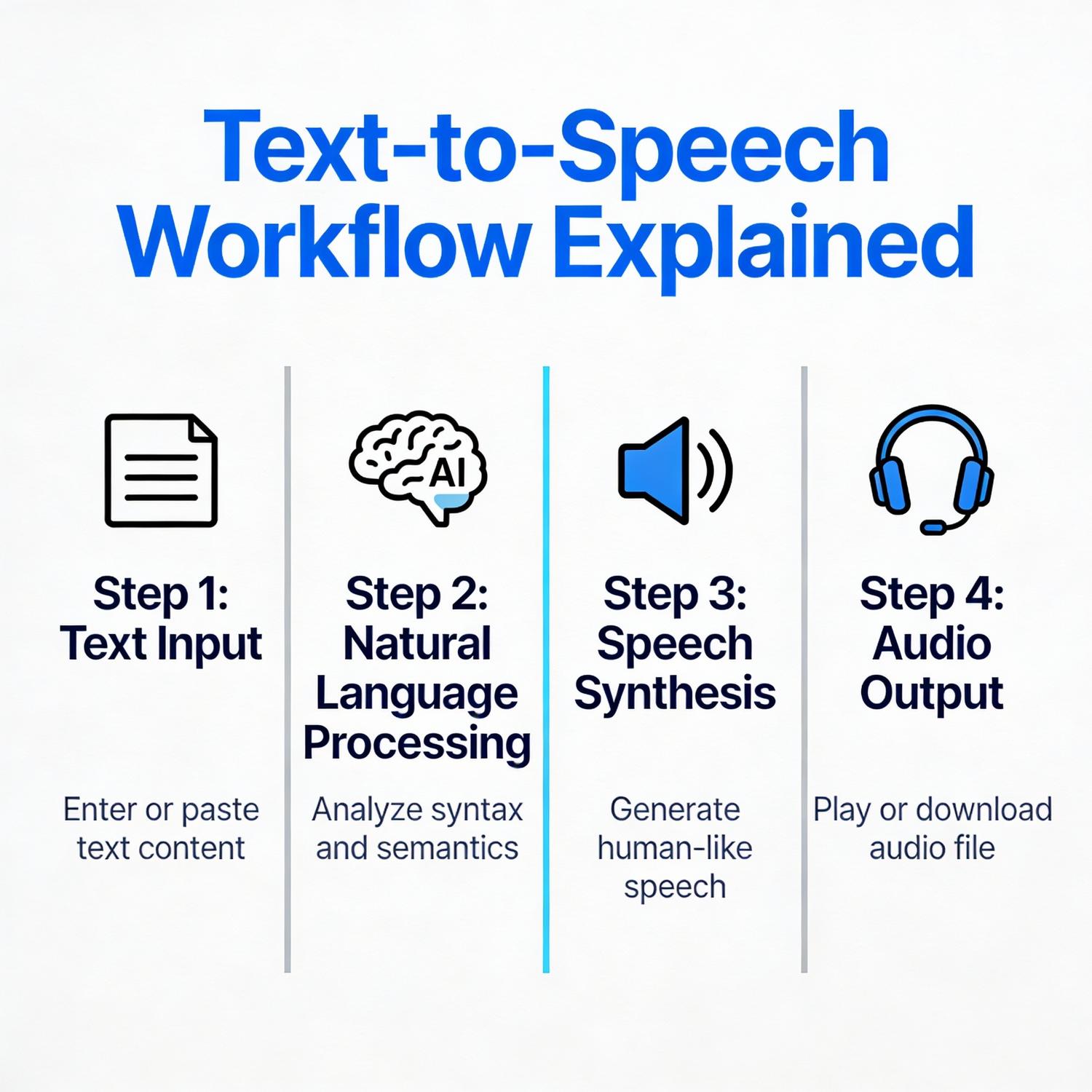
The evolution of speech synthesis technology has transformed how we interact with digital content. Modern systems now combine audio generation capabilities with sophisticated processing pipelines that handle multiple data types simultaneously. These integrated approaches enable developers to build applications that convert written content into natural-sounding audio while managing various input formats and output requirements. The convergence of text-to-speech workflows and MultimodalFlow architectures represents a significant advancement in how we design and deploy voice-enabled systems across industries.
Core Analysis
Contemporary speech synthesis systems operate through complex processing chains that transform textual input into audible output. These systems leverage neural networks trained on vast datasets of human speech, enabling them to produce remarkably lifelike vocalizations with proper intonation, rhythm, and emotional nuance. The underlying architecture typically involves multiple stages: text normalization, linguistic analysis, prosody prediction, and acoustic generation.
The integration of text-to-speech workflows and MultimodalFlow frameworks has enabled developers to create more sophisticated applications that handle diverse data types. These systems can process not only written content but also metadata, user preferences, contextual information, and real-time feedback signals. This comprehensive approach allows for dynamic adjustment of voice characteristics, speaking rate, and emotional tone based on the specific use case.
Modern implementations utilize transformer-based models that capture long-range dependencies in language, resulting in more coherent and natural-sounding speech across extended passages. These models can adapt to different speaking styles, accents, and languages with minimal retraining, making them highly versatile for global applications.

Use Cases & Applications
Speech synthesis technology has found widespread adoption across numerous sectors. In accessibility services, these systems provide essential support for individuals with visual impairments or reading difficulties, converting digital text into accessible audio formats. Educational platforms leverage voice generation to create engaging learning materials, audiobooks, and language learning tools that adapt to individual student needs.
Customer service operations increasingly rely on synthetic voices for automated response systems, virtual assistants, and interactive voice response platforms. These implementations reduce operational costs while maintaining consistent service quality across all interactions. Content creators utilize voice synthesis for podcast production, video narration, and multimedia presentations, dramatically reducing production time and costs.
Healthcare applications include medication reminders, patient education materials, and assistive technologies for individuals with communication disorders. Navigation systems, smart home devices, and automotive interfaces have also integrated advanced speech synthesis to provide intuitive, hands-free user experiences.
Challenges & Limitations
Despite significant progress, speech synthesis technology faces several persistent challenges. Achieving completely natural prosody remains difficult, particularly for complex emotional expressions or nuanced conversational contexts. Systems sometimes struggle with uncommon words, proper nouns, or domain-specific terminology, producing mispronunciations that disrupt the listening experience.
Computational resource requirements pose another significant constraint. High-quality voice generation demands substantial processing power, which can limit real-time applications on resource-constrained devices. Latency issues may affect user experience in interactive scenarios where immediate audio response is critical.
Ethical considerations surrounding voice cloning and deepfake audio present ongoing concerns. The ability to synthesize convincing replicas of human voices raises questions about consent, authentication, and potential misuse. Establishing robust verification methods and ethical guidelines remains an active area of development.
Cultural and linguistic diversity presents additional complexity. While systems perform well for widely-spoken languages, support for regional dialects, minority languages, and culturally-specific speech patterns remains limited. Expanding coverage while maintaining quality requires substantial investment in data collection and model training.
Future Outlook
The trajectory of speech synthesis technology points toward increasingly sophisticated and personalized experiences. Emerging research focuses on emotion-aware systems that can detect user sentiment and adjust vocal characteristics accordingly. These adaptive systems will provide more contextually appropriate responses in conversational interfaces.
Integration with other sensory modalities will create richer multimodal experiences. Systems that coordinate speech output with visual displays, haptic feedback, and gesture recognition will enable more immersive and accessible interfaces. This holistic approach will particularly benefit augmented and virtual reality applications.
Advances in few-shot learning and transfer learning will reduce the data requirements for creating custom voices, enabling rapid deployment across new languages and speaking styles. Edge computing developments will bring high-quality synthesis capabilities to mobile and embedded devices without requiring constant cloud connectivity.
Personalization will extend beyond simple voice selection to include individual speaking patterns, vocabulary preferences, and communication styles. Users will be able to create highly customized audio experiences that align with their specific needs and preferences.
Conclusion
Speech synthesis has matured into a foundational technology that powers countless applications across diverse industries. The sophisticated processing pipelines that enable natural voice generation continue to evolve, driven by advances in machine learning and computational linguistics. As text-to-speech workflows and MultimodalFlow architectures become more refined, we can expect even more seamless integration of synthetic voices into our daily digital interactions. The ongoing development of these systems promises to make digital content more accessible, engaging, and universally available to users worldwide.
Leave a Reply